Title: Sixth Sense – Feel What You Read
Team Members: Ameya Raul, Bixi Zhang, Shruthi Racha and Zhicheng Gu
Motivation – What is the goal of your project?
- Charity drive messages which were earlier powerful and emotive now seem plain have lost their intensity.
- In this day of age, pictures aren’t as moving, and statistics aren’t as impactful since nearly all the shock value has faded away. The issue is that most of us are so greatly distanced both physically and emotionally from those who need help.
- Donors are no longer as invested in philanthropic causes because non-profit organizations fail to create empathy, let alone an understanding of the problem. So what do you do now? Where does the future of fundraising lie for charities? The answer may lie in virtual reality.
- A powerful means to evoke empathy lies in virtual reality.
- Aim of the project – leverage virtual reality to bridge the emotional and physical disconnect between victims, non-profit organizations and the donors by achieving a visualization of articles pertaining to social causes in Virtual Reality.
- Journalism in 360 degrees : https://youtu.be/BuGUQ6svJyg
Part I
In the first part, we display social aspect videos when people are reading an article. We try the following two ways to display the text.
- Display the text and video at the same time. Users will see the text appears on the top of the video.
- Display text and video in alternate separate frames. Users will first see a part of text on a black background, then a part of video corresponds to the text will be shown.
Part II
In the second, we attempt to automatically display object animations based on the text content. We consider the following two approaches.
- Automatic object creation and placement in the scene. This requires all object animations to exist beforehand, and the relative placement of objects is tricky.
- Scene to phrase mapping. We try to involve mapping scenes in a video to each sentence in the text. Makes use of video tags for mapping
Related Work and Literature Survey
Literature Survey of prior art and case studies done along the lines of virtual reality used for Social Causes and Story Rendering.
a) https://pdfs.semanticscholar.org/1475/9c2226d24d3926b91b375d6fcd85cf403813.pdf
Research and User Experience testing of the various VR headsets available and evaluate based on features and aptness for the problem under consideration.
a) http://www.wareable.com/headgear/the-best-ar-and-vr-headsets
b) http://www.theverge.com/a/best-vr-headset-oculus-rift-samsung-gear-htc-vive-virtual-reality
Contributions – Describe each team-member’s role as well as contributions to the project.
Ameya Raul
- Deciding on the scale and positioning of the two spheres for stereoscopic vision
- Integration of Oculus with Unity
- Development of Code for multiple objects movement.
- Design and development of simulation of visualization of Streaming Text.
Bixi Zhang
- Trying various Video Formats and resolutions to determine the best combination to use in Oculus.
- Interposing of Text and Video Frames
- Design of various fonts of Text
- Design of different Text Placement Strategies and trying it in Oculus.
Shruthi Racha
- Deciding on the scale and positioning of the two spheres for stereoscopic vision
- Integration of Oculus with Unity
- Development of Code for multiple objects movement.
- Design and development of simulation of visualization of Streaming Text.
Zhicheng Gu
- Conversion of videos from one codec format to another using Ffmpeg.
- Extraction of audios from videos
- Development of Code for multiple objects movement.
- Design and development of simulation of visualization of Streaming Text.
Outcomes
- Describe the operation of your final project. What does it do and how does it work?
Our project comprises of 2 parts – The Social Aspect and The Automation. For each of these, we developed and compared 2 approaches.
a) The Social Aspect
Both of our approaches are aimed at figuring out the best user experience with respect to the coordination of text and video.

- Approach 1: Display text as the video runs
In this approach we display text near the center while the video progresses. To account for user’s turning around, the text is displayed at 3 angles, 0, 120 and 240. Text is displayed on top of a semi transparent background in order to ensure easy readability.
We experimented with moving the text to the bottom of the video (like a subtitle). However, because the video is projected on the inside of a sphere (to guarantee 360 degree vision), the text appears squished if placed anywhere other than near the center. We also attempted to move the text along with the user camera. The user found this particularly irritating because the text blocked out whatever he moved his head to look at.
The major drawback is that the text blocks out some useful info in the video. The text also seems to shatter the presence felt in the virtual world.
- Approach 2: Display text on separate frames
To overcome the drawbacks of Approach 1, we experimented with placing text intermittently within the video on separate frames. A small paragraph (2 – 3 sentences) is displayed in white on a black background followed by a corresponding video segment.

This experience fairs better. Unlike the previous approach where users were compelled to read text and look around at the same time, this approach allows the user to focus on only one thing at a time. Moreover, the user can focus on different aspects of the video, thereby increasing immersion.
b) The Automation
In this phase of our project, we attempt to automatically display object animations based on the text content.
- Auto-Animation
In this approach, we attempt to display objects and apply animations to them based on the text. For example, if the text is “There is a tree. It is raining”, we would display a tree and make it rain. The subset of objects and move functions is formed by parsing the input text and forming a sub dictionary from the superset dictionary of pre created objects, e.g, ball, tree and raining.

We require that all objects are present in the inventory. When the application runs, Unity selects the appropriate object (using a dictionary of mappings) and displays it at the appropriate position. The fact that a library of all possible objects and animations is required places a limitation on the scalability.
It is difficult to control the relative placement and movement of objects. Moreover adding environmental constraints such as gravity may limit the application to imaginary lands with magic (e.g where balls can move up without coming back down).
- Video Segment Mapping
To overcome the above drawbacks, we shift to a more scalable and simpler approach. This involves dynamically displaying different segments of videos according to the sentences in an article. This requires a collection of video segments, where each segment has a set of ‘tags’. A tag is a single word description of an important aspect of a video. We then proceed to match each sentence in the text to a segment of the video. This is done by choosing the video segment which has the most number of tags in common with the sentence. We then proceed to stitch the videos in the order of the text.
We leverage Unity’s 3D Text for displaying the sentence when the corresponding video plays. Text is displayed at the center of the video only at an angle of 0 degrees (In front of the user). Text is displayed in white, which contrasts it with its surroundings, making it easier to read.

For the scope of this problem, we restricted ourselves to a video called “The Source” which deals with water shortages in the desert. We segmented this video and manually assigned tags to each segment. We then created multiple articles on water shortages to observe how the experience changed each time. We were even capable of creating a completely opposite story where the borewell is dug first (which dries up) so people have a water shortage later on.
We observe that the user experience was drastically better. User’s were able to relate the sentences and the videos, and the fact that these videos were based on real incidents, increased the sense of presence in the environment.
2) How well did your project meet your original project description and goals?
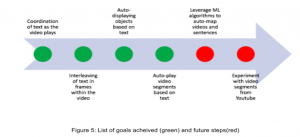
Throughout the course of our project we have stayed in line with our initial vision – Visualization of a social article in VR and Text based automatic animation rendering. The latter part was too ambitious to complete within the scope of this project, however we are content with the approaches we were able to explore and the extent to which we could convert “Text based automatic animation rendering” into a working proof of concept. Given the opportunity, we would love to experiment more by introducing Machine Learning algorithms such as Artificial Neural Networks to auto map text to objects by leveraging a dataset (e.g. Imagenet). Figure [5] highlights the goals we achieved over the course of the project.
3) As a team, describe what are your feelings about your project? Are you happy, content, frustrated, etc.?
As a team, we feel happy and satisfied with our progress over the course of the project. We feel we have been able to leverage each team member’s skill set to the maximum in various aspects of the project ranging from design, programming to time management and team dynamics. We feel more confident when dealing with Unity issues. We all enjoyed playing with the Oculus Rift. Overall we feel that the project was a great success and one of the salient features of the class.
Problems encountered
We encountered a myriad of issues pertaining to either Unity or the logic of our project. Following is a brief overview of the significant ones.
Part I
- Positioning of text within a video : This was a design question. Which positioning yields the best user experience? Moreover, positioning text away from the center resulted in distortions. Positioning was important to increase presence.
- Importing Videos in Unity : Adding videos to the asset folder took large amounts(e.g. 20 minutes for a 2min 240p video) which restricted us to low resolution short videos.
- Ensuring Readability: Setting an appropriate text size and the width of the text box was important to ensure readability in low resolution videos.
- Resolution of the video: We got the video with the highest resolution, but it still seems not good in the Oculus. This is probably because the importing process of Unity or the videos lost some quality when we edit them.
Part II
- Relative Positioning of Objects: It was difficult determining where auto-generated objects should be positioned relative to each other in an environment. Auto generating terrain and a detailed scenery was far beyond our scope as all objects needed to be created before hand.
- Relative Movement of Objects: Capturing all kinds of motion of objects was a difficult task in itself, but now capturing the interactions of movements of different objects with each other (e.g. what happens when 2 objects collide, do they bounce back, or do they explode?) was tricky. Moreover, dynamically adding constraints (based on the text, e.g. brooms can fly if you are in a Harry Potter based VR environment) to restrict object movements in a virtual environment is a difficult problem.
- Gather Video Segments: Creating a set of video segments that would pertain to all different combinations of text is difficult.
Next Steps – We envision the following next steps for our project :
Part I
- Move the text with the camera. Allow the user to zoom in/out or move it using the controller.
- Figure out a way to bypass Unity’s bottleneck and import higher resolution videos. We need to make high resolution videos to get better reading experience.
- Experiment with superimposing 3D text on top of videos
- Allow the user to move the text with a separate controller
Part II
- Creation of multiple objects and corresponding move functions to co-exist in a scene.
- Using machine learning and deep learning for automatic visualization of articles, rather than the static way which is the current approach.
- For the experiment, we tailored our own video segments and tags, however obtaining such a set from youtube and experimenting with that may be more realistic.
Video of the Project in Action
We present the following 4 videos, each demonstrating an approach for a part of the project
https://drive.google.com/open?id=0B2lCWzhongHOSERteU1SVGJJTGM
https://drive.google.com/open?id=0B2lCWzhongHOYWVzUmI5S1k1Wnc
https://drive.google.com/open?id=0B2lCWzhongHORGRDZXNoWm5lbUE
https://drive.google.com/open?id=0B2lCWzhongHOLXhudS1BejZKNjQ