The last couple of weeks I have been working on visualizing CONDOR cluster data in our system, that is either the CAVE, the devlab etc.
Currently, the output looks something like this:

Current cluster monitor.
Each single cell represents a slot which can run an assigned job. Multiple slots are part of a node (a single computer) and multiple nodes are formed into groups. The coloring depicts the load from blue (low load = bad) to green (high load = good, efficient). Red nodes show offline nodes, black ones have missing information and grey ones are occupied otherwise. This display is updated every 20 minutes.
The approach I took was separating everything into their hierarchical structure: slots into nodes into groups:
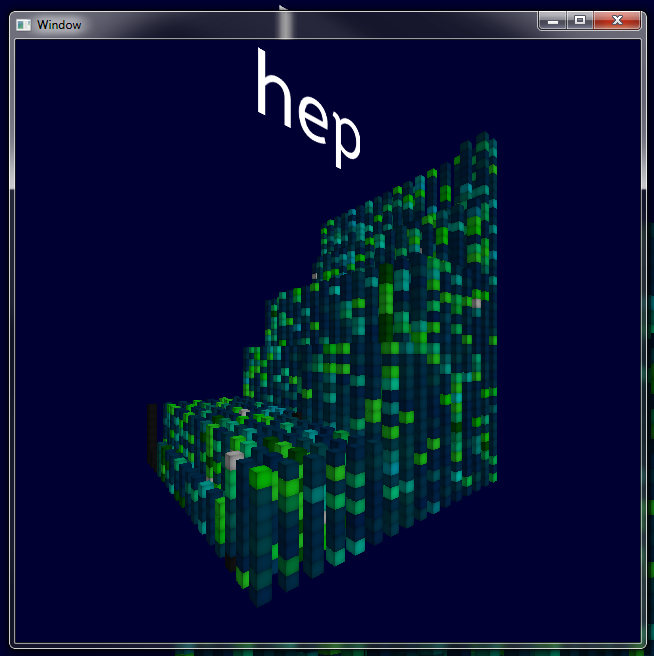
The high-energy physics group
This is the high-energy group. Many computers and you can tell at a glance that these computers are quite powerful, as they stack really high. Most of them are running jobs at different efficiency.
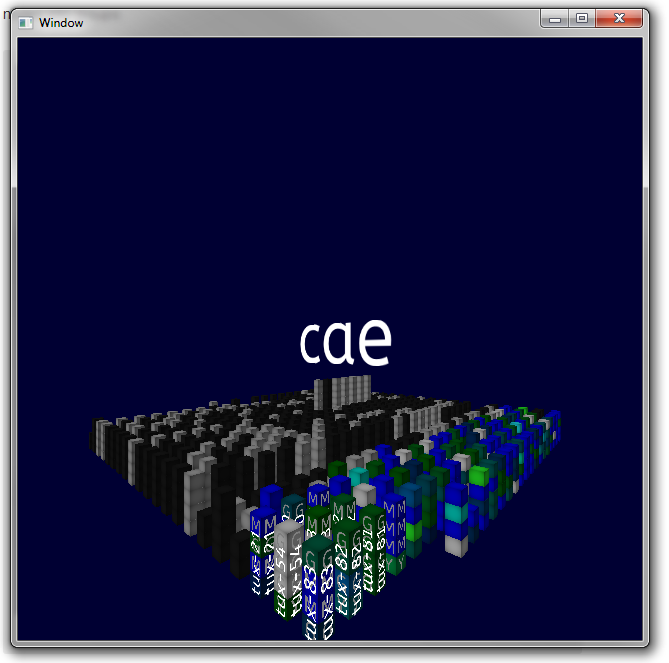
The cae group
The cae pool, on the other hand, looks completely different. Many low-powered computers with 4-8 cores, which are also not accessible (grey or black). If you move closer to the nodes, a single letter per slot shows you which job group this job belongs to. Many jobs are recurrent and therefore have their own letter (for example, Y or G). Overlaid in white is the short node name.

The cluster in action
The best thing is that we have multiple log files and we can cycle through them. Not only can you see how jobs move through the cluster and load changes, but also how the groups grow and shrink if new computers join the group or are going offline.
There are also two main data highlights in here the load view, as above, and the job view, in which the same job class is highlighted throughout the system.
Seeing this visualization in the CAVE is very interesting as you are surrounded by these massive towers. The CHTC group liked it very much so far and we will demo this system next week during CONDOR week 2014.